概述
上文【异常检测】独孤九剑之破剑式——无监督算法中,我从异常域和算法域两个维度总结了异常发现的视角和方法。但是只知道这些招法,不免味道寡淡,且有形无神。就像岳灵珊进入思过崖山洞,速成了五岳剑派丢失数十年的许多绝招。在五岳合派大会上横扫了一些三流角色,但戏份和境界也只能止步于此了。那么本文,我会与大家分享我在应用这些异常检测技术时,踩过哪些坑,发现了什么小技巧。希望能给大家一些心法上的提示吧。
最佳实践
偏离多少是异常
处理过相关不平衡数据集的同学肯定有过这个疑问,不平衡变得多大时它应该被认为是一个异常。是应该相对来看吗,一串0构成的序列中插入一个1,偏离度无限,是异常吗?那绝对来看呢,输错密码异一次肯定不会是异常,那几次算呢?
所以虽然上文在如何评价无监督算法章节中介绍了一些异常分的算法,但任何场景通用的评分函数其实是不存在的。算法给出的统计异常、密度异常都是数学角度的离群点,并不能直接对应到业务异常。所以设计异常分值算法时,一定要紧贴业务,引入业务系数或者阈值。接入新业务时,一般就只需要对这两个参数做适配就可以了。
除了输出0、1判断和0-1的异常分,还可以考虑使用分段的异常级别。如低危-中危-高危-极危。异常级别相对于异常分数更为直观,也便于在业务规则中使用。
如何处理业务变化
常见的业务变化主要有两类。一类是像双十一这样的大促,根据促销时长业务数值会出现区段的整体上升,或者短促的尖峰。同时为了保证业务数据正常流动,很多防护策略会做一定的让步。两方面的原因对数据扰动特别大,但好在大促事件我们都是提前知道的,可以做一些应对。如果有上线策略,那本着业务优先的考虑先降低告警阈值。然后从周期性考虑,可以差分后做年度的周期性模型。短周期模型中,这部分尖峰数据建议去掉,或者对大促单独做模型。
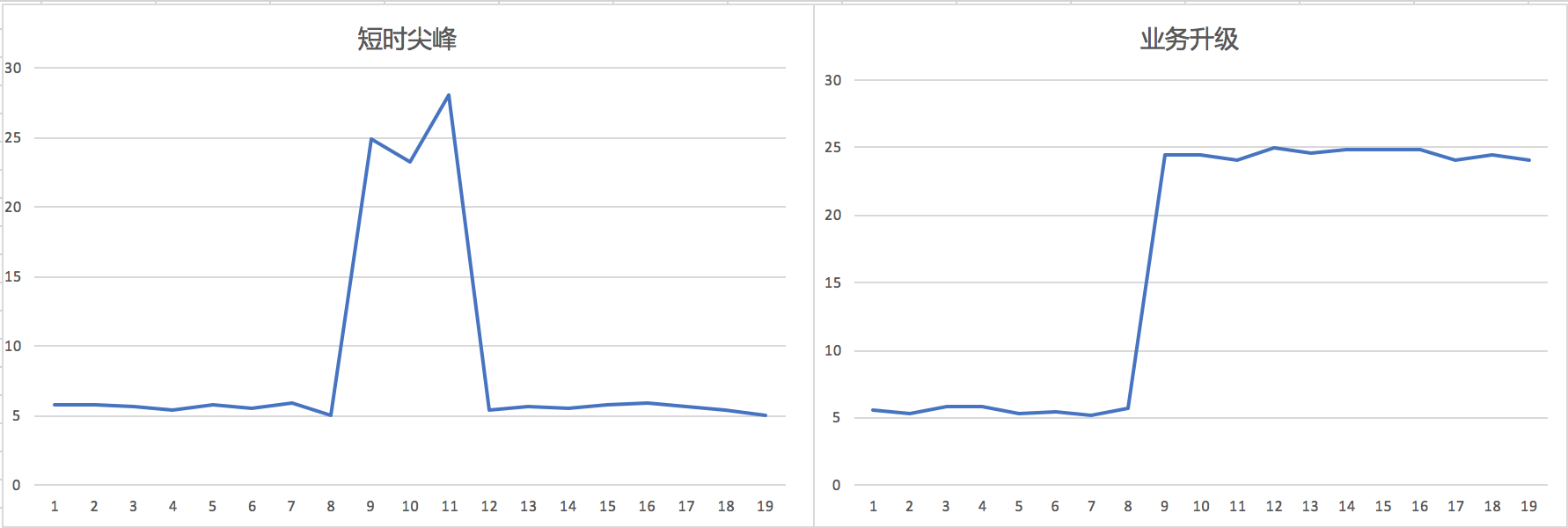
第二类是在某个时间点,新版本上线,业务曲线的区间发生突变。这种时候如果我们使用的是动态基线类的模型,那么即使不管,一段时间业务稳定后,模型也会自动适应,只需忽略掉突变期的误报。如果是非动态模型的,至少需要在业务稳定后,手动触发新模型的训练。
异常点合并
有时候,攻击可能是持续发生的,那对应异常在时间上也是持续的。在CEP中会有Contiguity within looping patterns的问题。如A连续登陆失败5次ABCDE,如果规则写的是连续4次及以上为异常,那么不同的规则引擎可能输出不同的结果:(1)ABCD,ABCDE,BCDE (2)ABCD,ABCDE (3)ABCDE。另一种情况,规则要求顺序匹配三个事件ABC,如果实际事件发生为ABBBC,那么不同的规则引擎可能输出:(1)ABC,ABC,ABC (2)ABC,ABC,ABC,ABBC,ABBC,ABBC(3)ABC,ABBC,ABBBC。熟悉CEP的同学知道这里采用了不同的匹配策略:Strict Contiguity,Relaxed Contiguity,Non-Deterministic Relaxed Contiguity等。
我个人认为,告警应该做到尽量紧密。只要是各个属性相同的告警,在一个时间内的,应该计数合并。持续发生的,应该记录起始时间,在时间轴上持续显示,相应告警级别也要逐渐提升。
online的无监督算法
离线算法虽然容易实现,但实时场景才是更高的追求。在线算法各方面的优势对业务方有着巨大的吸引力。在线算法实时接收增量数据,并通过增量数据对模型进行调整,而不需要从头训练整个模型,即节省了空间也节省了时间。然而面对海量级的数据流,要保持一个无监督模型是在线的甚至是分布式的是很有挑战的。
有的模型比较容易改造。比如基于概率分布的,概率后缀树每学习一个新序列,只需要在原来的概率树上更新某条路径上各节点的概率。概率树的模型大小至于序列的多样性有关而与数据的绝对规模无关。基于矩阵分解的个群基线也有在线的版本Online Robust PCA via Stochastic Optimization(NIPS 2013)。另外矩阵分解也有GPU加速的底层库,真有大规模的应用场景,技术上一般问题不大。
单次迭代就要依赖所有数据的,online版本肯定会遇到问题。类似KMeans的聚类算法先天就能够支持在线计算,但是复杂度会随着数据规模增加。再看神经网络,从模型上讲使用增量数据二次训练的模型似乎跟用全体数据一次性训练的结果应该一致。但是实践显示,二次训练的模型往往达不到一次性训练模型的准确性。Isolation Forest也有在线版本的论文,但实践还是比较少。
最后但凡能够使用滑动窗口的业务模型,都可以做到T+1的mini batch模式。有的模型甚至能够直接输出边界,新的数据做检测时直接比对边界就可以了,而不用通过复杂模型,从而大大增强性能。
时序数据处理
首先需要关注的是周期选择,配合业务特性选择分钟、小时、日,周,月,年。选择长周期时序处理时注意先差分去掉趋势。
简单时序的话业界有一些开源的算法包,如Netflix的R语言包Surus,Yahoo的Java包EGADS。
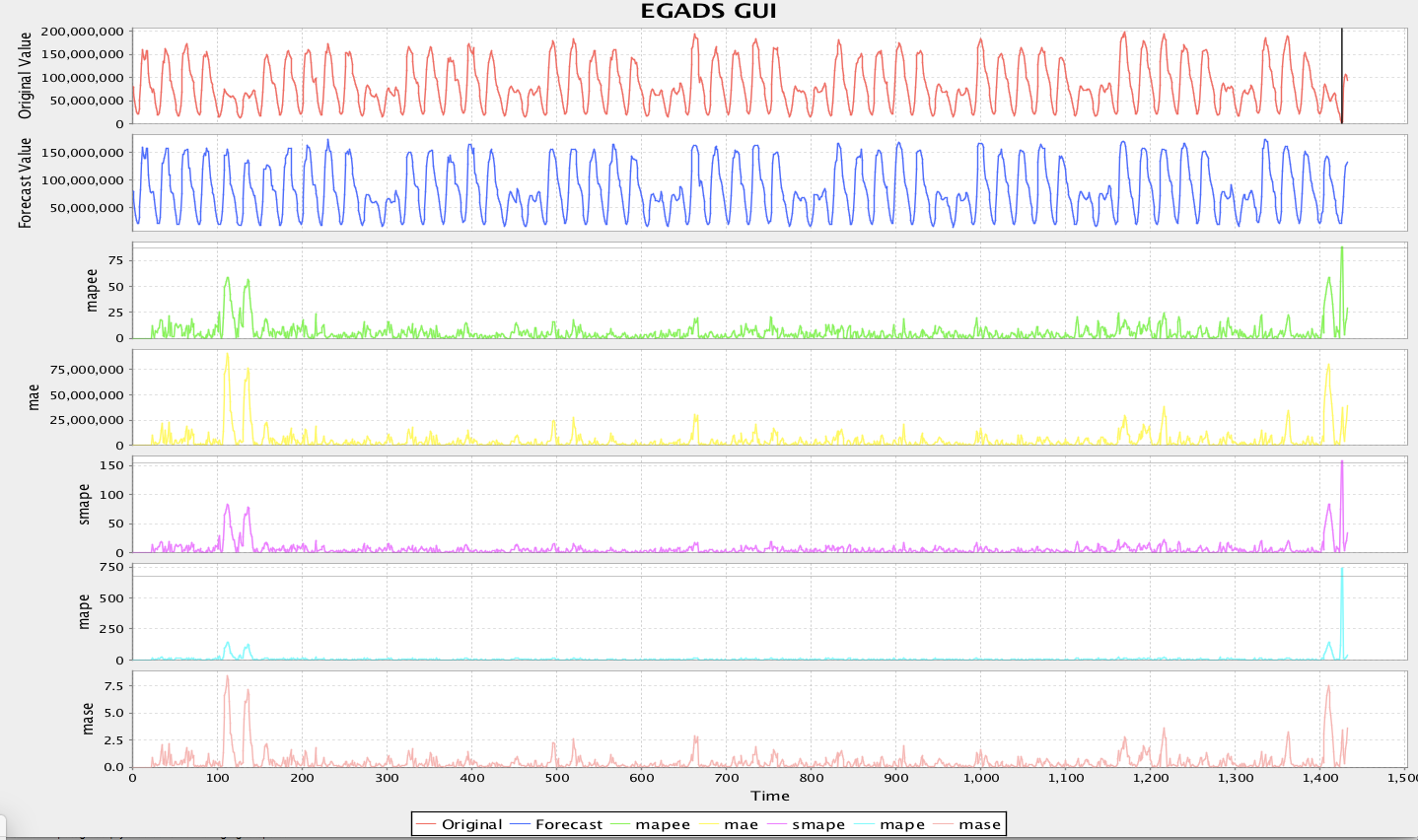
常见操作是我们需要去拟合输入序列。那不同类型的数据可能适合不同的模型。EGADS中选择AutoForecastModel,程序会自动把所有TMM都跑一遍,并推选偏差值最小的模型送入异常检测模块。这里值得注意的是,自动选取只关注了还原度,但还原度高并不直接代表能更好的查找异常,在使用本方法的时候要留意在心。
另外模型选择时使用多数投票法,不论在局部或者全局异常发现中,都是非常有效的。
密度聚类的特点
密度聚类时可能存在三种情况。如果使用DBScan,那无法聚到类中的游离点是异常,点数较少的类可能是异常。但是如果数据主体是某些PV量较小的接口时,最大的类可能全部都是异常。这又给智能运维提出了很大的挑战,单纯依赖异常检测,黑白都可能会反转。一个非常有效的方法是引入领域知识做二次判断。比如在安全领域,可以引入威胁情报。访问IP是否是高危IP,UA是否是恶意UA,IP、账号是否关联了恶意域名等等。
噪音问题
 数据集中存在系统性或者语义性的噪音是非常正常的。相比噪音,分析者更感兴趣的是异常点。
数据集中存在系统性或者语义性的噪音是非常正常的。相比噪音,分析者更感兴趣的是异常点。
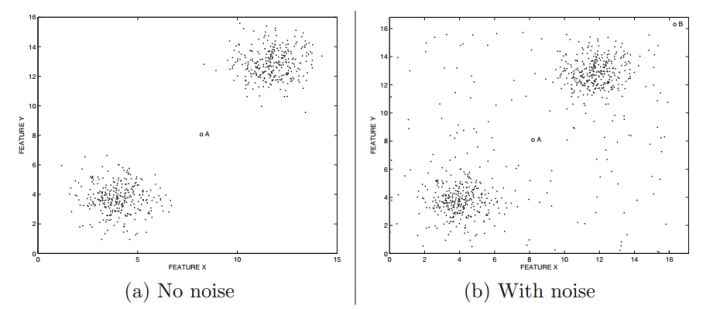 但噪音与异常点在数据表现上并不容易分开,可以看上图(a),当没有噪音时,我们可以认定A点就是异常点,然而当存在大量噪音时,如上图(b),点A附近有大量分布稀疏的点,当我们收起上帝视角时,你并没有很大把握判定A点就是一个异常点,因为与它相似的点还有很多。在基于密度的聚类中,噪音点会极大的影响质心的位置。在基于统计的模型中,会极大的带偏系统参数。这种两种情况都必须想办法清楚噪音。如果噪音点数量过多,类似于DBScan的方法会直接失效,数据点可能会连成一片。这时候除了手动筛选以外,最直接的方法是降低采样频率,降低整体数据的连接度。
但噪音与异常点在数据表现上并不容易分开,可以看上图(a),当没有噪音时,我们可以认定A点就是异常点,然而当存在大量噪音时,如上图(b),点A附近有大量分布稀疏的点,当我们收起上帝视角时,你并没有很大把握判定A点就是一个异常点,因为与它相似的点还有很多。在基于密度的聚类中,噪音点会极大的影响质心的位置。在基于统计的模型中,会极大的带偏系统参数。这种两种情况都必须想办法清楚噪音。如果噪音点数量过多,类似于DBScan的方法会直接失效,数据点可能会连成一片。这时候除了手动筛选以外,最直接的方法是降低采样频率,降低整体数据的连接度。
工作流的创新
首先不得不承认,基于无监督的异常检测是非常依赖运营的。那如果能提升运营的效率,也是和集团节能降费提效的工作目标非常契合的。
传统工作流是将算法异常作为告警提交给运营同学做判断。那显而易见的问题是上下文不完整,误报高,海量告警无法处理。
好一些的工作流增加了一层数据抽象,即威胁场景。威胁场景描述完整的攻击链条,包含多个通过场景规则关联到一起的告警。一方面将告警浓缩到场景,可以减少两个量级告警数量。另一方便,场景规则有效关联的告警通过相互印证,准确度是非常高的。单点异常来源的告警在这个环节自动被忽略掉了。
运营的打标数据反馈到模型上,通过半监督算法提升模型准确度。这个虽然是我们强调的闭环的重要构成,但在实际应用中有诸多问题。那取代这个闭环的最新研究成果是无监督聚类->人工标注->有监督学习,以实现对已知场景的case by case击破,同时保持对未知异常持续发现的能力。
小结
那么以上八点就是我在工作中总结出的一些经验技巧了,希望能够帮助到有需要的同学。
comments powered by Disqus