今年7月25日,我所在的公司瀚思科技在北京宣布完成B轮融资一亿元人民币,并且发布了新一代的病毒检测产品DeepSense。Deepsense可以做到沙箱同等水平的高检测率99%,而误报率低于1/1000。
7月27日,在2017网络生态安全峰会(前阿里安全峰会)人工智能与安全分会场上。我代表瀚思科技第一次披露了Deepsense的技术细节。11月16日,在InfoQ AI前线组织的瀚思安全月第三讲中,我又给大家介绍了最新的一些进展。这次分享有16个群的朋友同步在线收看,下面是分享的图文实录。
各位晚上好,首先感谢大家参与我的这次主题分享,同时也感谢 InfoQ AI 前线组织这次瀚思科技主题月!

瀚思科技成立于2014年,按行业划分我们是一家安全公司。但和大家熟知的卖杀毒软件或者防火墙的传统安全公司不同。瀚思科技帮助各种中大型企业搭建安全大数据的分析平台,平台上应用的安全分析策略深度结合了多种机器学习算法,最终帮助企业定位与揭示各种安全问题。所以我们自己定位是一家安全+大数据+AI的公司。

在瀚思科技首席科学家万晓川的带领下,瀚思算法部门紧追时下AI领域最前沿的技术突破,并尝试应用在安全领域当中。今天是主题月的第三讲,接下来我会为大家分享我们是如何利用深度学习来做二进制恶意样本检测的。

agenda如上图所示,考虑我们主要的观众是大数据和AI方向的,我会首先介绍一下病毒检测的技术沿革,各种技术的优劣和取舍。然后我会说明为什么我们认为深度学习可以很好的应用于病毒检测。具体我们是怎么应用深度学习的,用的什么网络,中间有什么技巧。最后是实际操作后,我们得到的一些经验教训,以及下一步的发展规划。

如图所示,我们可以笼统的把病毒检测的各种技术根据两个不同的维度来进行区分。一是根据数据源可以分为基于内容和基于行为两种。二是根据检测方法分为:基于特征码、基于规则、基于算法。
基于内容的就是一般所谓的静态分析,病毒样本不需要实际执行起来。安全人员直接打开文件查看二进制码或者反汇编后来分析源代码都算静态分析。熟悉安全领域的朋友会注意到这里有个加壳的问题,加壳的样本,尤其是复杂的壳,要做反汇编其实并不容易。内容结合特征码就是传统的病毒引擎的原理,我们日常在都在使用。依赖安全人员给出精准匹配的特征码,匹配迅速,但是就如我们的杀毒引擎一样,需要定期更新病毒库。
基于行为的就是一般所谓的动态分析,需要在实际或者通过虚拟化的方法把病毒样本执行起来。通过考察样本对操作系统各种资源的操作来构建特征和分析。某些大病毒家族,比如勒索软件,因为操作高调,通过动态分析非常好识别。
基于规则的方法在静态分析领域用得很少,算是补充。但是在沙箱领域非常常见,因为病毒行为很容易写出规则来。但实际的情况是病毒在沙箱内运行的时间短,最多就是30分钟,往往10分钟都不到,导致其行为暴露不够充分。
运用分类算法基于行为特征来检测看似不错,但是行为特征少是一个明显的缺陷。所以很多时候往往是混合了动态的和静态的特征来构建。
运用网络行为加算法来分析就是目前比较火也很有前途的NTA(Network Traffic Analytics)。NTA既融合了传统规则,也结合了机器学习,通过监测网络的流量、连接和对象来识别恶意样本产生的行为。再配合上质量好的威胁情报,能产生高信息熵的特征,特别适合Botnet这一类的病毒。
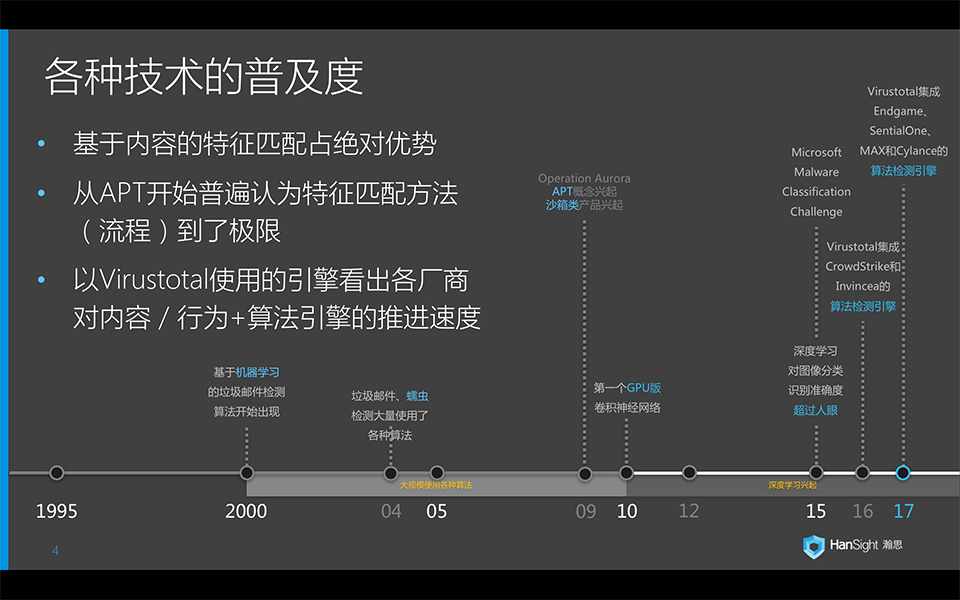
在历史沿革和普及度上,我们需要知道在业界中,基于特征码(也就是内容特征匹配)的技术仍然占有压倒性优势。统计发现,只要能拿到对应的病毒样本,各大杀毒引擎厂家都能在3小时左右部署特征码。但这个工业流程到达极限以后,厂商在后台拿到新样本的速度很难再提高(APT也难拿到样本),要么是拿到了也处理不过来(新病毒的产生速度一直在提高,有报告统计出每4.2秒就有一个新病毒产生)。一般我们普遍认为,在APT开始大量出现后,特征匹配的方法(流程)到了极限。
如上图时间轴,考察Virustotal中集成的新引擎,可以看出各个厂商应用内容/行为+算法模式的推进速度。安全厂商普遍使用机器学习算法是从2000年开始的垃圾邮件检测,从最初的简单贝叶斯到04年的SVM。我们安全行业采用算法的速度并不落后于其他行业,衡量标准是安全厂商的数量。而学术界更早就有用算法解决安全问题的文章。前面提到09年后APT兴起,伴随着是沙箱类产品的兴起。2010年第一个GPU版的卷积神经网络出现,在图像识别领域飞速发展,网络变得越来越深,越来越大。到15年,基于深度学习的图像分类识别,其准确度已经超越了人眼。同年,微软开办了第一届恶意软件分类大赛(Microsoft Malware Classification Challenge)。虽然当年拿下第一名的队伍后来被爆出投机取巧了(后面还会讲到细节),但是MS的竞赛让很多厂商学到了实际的样本分类算法应该怎么去做。到16,17年的时候,Virustotal已经集成了诸如CrowdStrike、Invincea、Endgame之类的基于算法的检测引擎了。

我们再快速做个对比。基于行为的也好,基于内容的也好,方法本身并无明显的优劣,但是部署场景有着明显的区别。瀚思做的是2B端,所以如果做行为分析,只能依赖于把样本放入沙箱里跑,没法从已经感染了病毒的一个客户实际的电脑上收集到病毒实际的行为。同时现在反沙箱技术实在是过于普及,倚赖沙箱技术会导致病毒检测率的天花板很低。如果做内容分析,又容易被加壳技术干扰。对应非文件类型的样本,如寄存在内存中的木马等无法支持。考虑到瀚思没有终端检测的产品线,加上技术团队做沙箱出身了解其弱点,最终选择了内容+算法的路线。另外2B还有个优势是能看到样本的额外信息(安全设备日志),比如是从那个网站下载的,是哪封邮件的附件,这些可以帮助我们降低误报率。

第二部分我们讲讲为什么深度学习适用于病毒样本分类的问题。
首先是效果足够好,在图像识别、语音识别、机器翻译等领域的效果都远远超过非深度学习的算法。第二是样本的性质合适,深度学习就是擅长处理单一类型的数据。对应我们的输入都是二进制文件。第三要求足够多的样本,而样本越多准确的也越高。病毒的样本呢,根据Symantec在今年Q2的统计,单日样本可以达到300万。第四,可以避免人工去选择特征,只要一开始就设计好网络结构,深度学习会自动学习到重要的特征。再对比静态分析,比如用N-gram,特征数量会轻松突破百万,再乘以上面的样本数,机器学习是必然选择。
总得来说,深度学习的优点(超多特征,无需人工特征,样本越多越好)都非常适合二进制病毒样本分类这个领域。目前我们也尝试应用深度学习到其他安全场景中(基于NLP的智能运维),但因为安全系统属于机器学习的下游,一般安全领域不容易直接产生对机器学习新思路突破,经常是借鉴上游的突破(如图像识别),所以还有很多安全领域等待我们去应用新的机器学习算法。
唯一的缺点就是深度学习目前还相对黑盒,研发人员和客户都还不容易理解,相关人员也不好招聘。
那么问题来了,我们的输入是文件,深度学习的输入是图像、语言、文字。中间如何转化?选取什么样的网络结构?
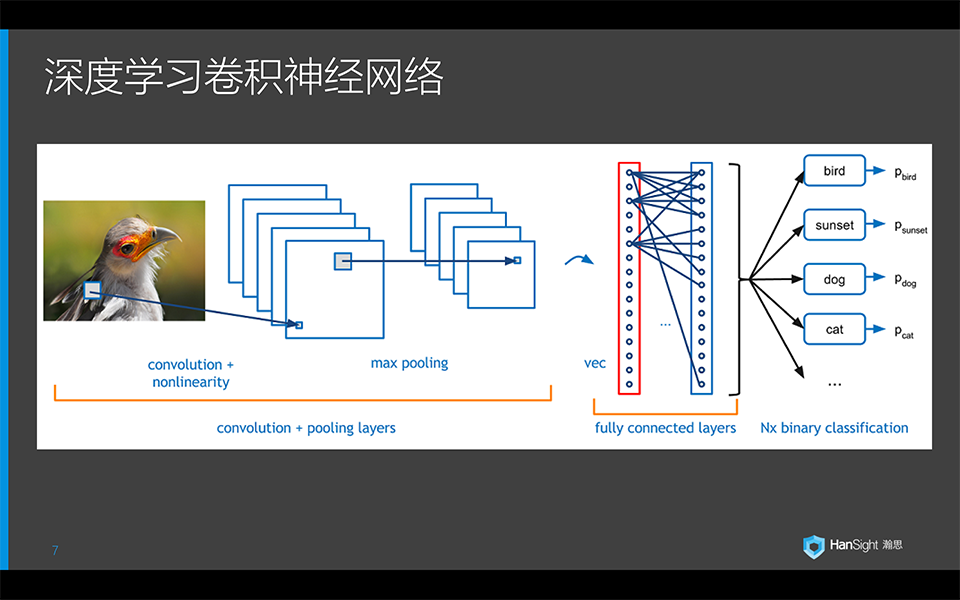
什么是深度学习?2012年的ImageNet大赛中,Alex Krizhevsky凭借AlexNet一举把分类误差的记录从26%降到了15%,震惊了世界。而AlexNet的核心就是上图中的卷积神经网络。网络的输入是图像,输出是该图像对应的分类。顾名思义,卷积神经网络包含多个卷积池化单元,其中包括了应用卷积核的卷积层,进一步降维的池化层。做完特征检测后,接入全连接层,观察输出特征与哪一分类最为接近。最后通过一个分类器得到分类的结果。
一般笼统的说法,越深的网络就代表更好的分类结果。但目前最新的一些网络模型都参考了resnet的理念,也就是很多个少数层的block组合而成,理念类似ensemble method,看block的构成和block的组合。 对于这个样本分类来说,我们前后换过几个resnet变种,目前部署的模型是基于inception-v4,但目前正在实验densenet,因为同等检测率下,参数更少计算更快。在客户环境下部署,我们希望尽量降低对硬件的需求。从我们实验的效果看,从早的resnet到新的inception-v4,迁移学习后差别只在5%内。所以今后我们研究的重点在速度了,网络选择是第二位。
之前我们提了一个问题,我们的输入是二进制样本,而卷积神经网络的输入是图像,怎么办?其实这个问题有两层含义,第一,我们需要把二进制样本通过一种方法转换为图像。第二,我们需要借助图像分类的经验甚至是特征模型来帮助我们做病毒的分类。
那么具体讲解我们的工作流之前,我们先引入一个概念:迁移学习。
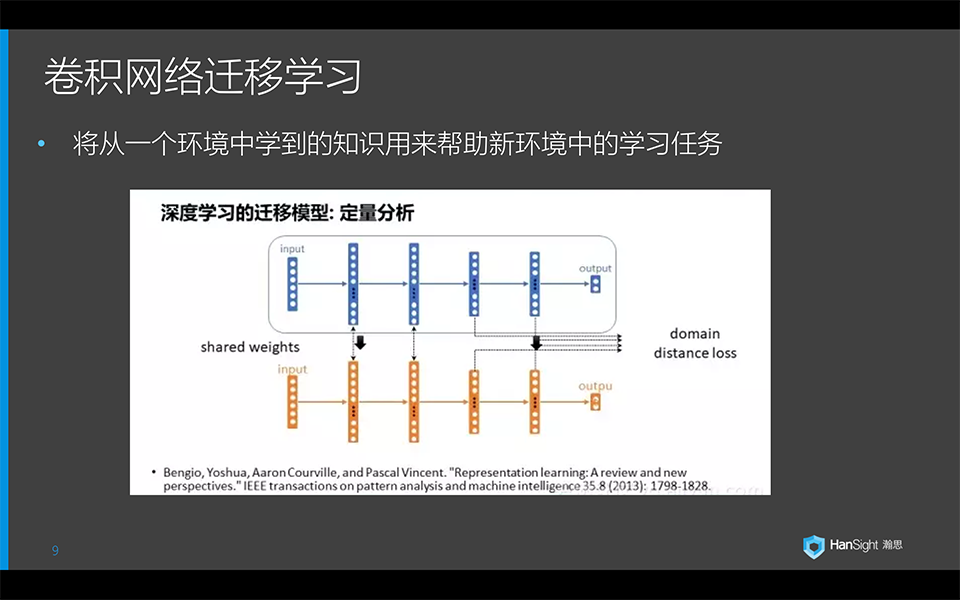
在今年的CCAI上,香港科技大学教授杨强又跟大家分享了什么是深度学习的迁移学习,这里借用他一张ppt。现在我们有两个近似领域A和B,通过深度学习自动提取特征以后,我们发现两个领域在浅层网络中的低级特征其实是可以共享的,而在深层网络中因为领域不同而对应了不同的高级特征。一种普遍的情况是领域A有大量的标记数据,有优良的特征模型已经生成。而领域B数据量比较小。那么通过共享特征,我们可以应用迁移学习将适用于大数据的领域模型A借用过来,再通过领域B的标签数据去训练高级特征和分类,从而在领域B上实现更好的分类效果。
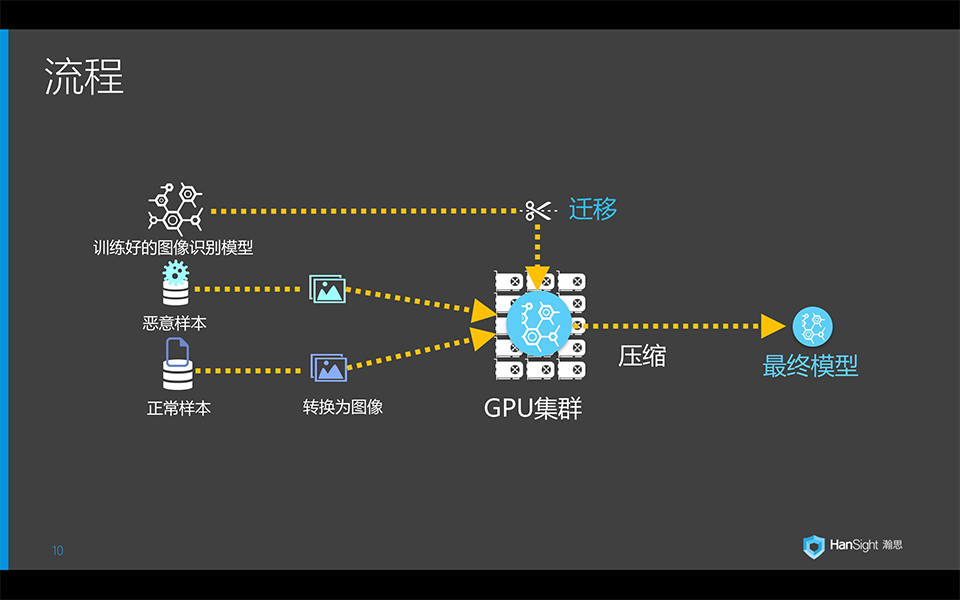
所以我们的流程如图所示。将正负样本按1:1的比例转换为图像。将ImageNet中训练好的图像分类模型作为迁移学习的输入。在GPU集群中进行训练。我们同时训练了标准模型和压缩模型,对应不同的客户需求(有无GPU环境)。

流程中比较核心的算法其实在文件到图像的转换。因为常规的网络一般能输入的尺寸也就是300 x 300上下,也就是9K左右的规模。而病毒样本的大小平均接近1M,是远远大于这个尺寸。图像领域的常规转换方法就是缩放,或者用pyramid pooling。这两者我们实验效果都非常低差,AUC在0.6左右。所以后来我们又设计了一个很复杂的pooling算法处理大尺寸文件。

前面我们介绍过,加壳的样本会对基于内容的分析造成影响。实验中我们发现文件A和B经过加壳后转图像。肉眼看过去,A和B的相识度会比以前更高。就好比PS中马赛克一张猫和一张狗的图片,马赛克强度越高,两图片处理后看起来越相似。但马赛克(加壳)强度低的话,其实处理后的图片和处理前的图片有一定的高纬度映射关系(加壳前后有对应关系)。这种关系,实验看起来深度学习网络能够分辨。当然强度大就无能为力了。 假设算法目前是分辨猫狗照片,不管有没有马赛克。但训练照片中,只有猫照片有马赛克处理,狗没有。所以人工产生狗马赛克图片(人工对样本加壳),让算法有更强分辨能力,至少是对弱马赛克后的图片。
高强度马赛克的话,算法只能记住高强度马赛克后的特征,只是如果有额外信息,比如图片出现在的邮件正文有猫或者狗的字样,就能辅助我们判断(引入其他信息)。

流程中提过我们训练了双模型,一个的Inception-V4,一个是Squeezenet。Inception-V4是目前较为先进的模型,有最好的实验结果,训练和inference的速度也可以接受。而Squeezenet是压缩模型,参数数量只有AlexNet的1/50,虽然准确度稍差,但检测速度快很多,专为不能提供GPU环境的客户设计。另外针对这两个模型做迁移学习的时候,我们都替换掉了最顶和最低几层。
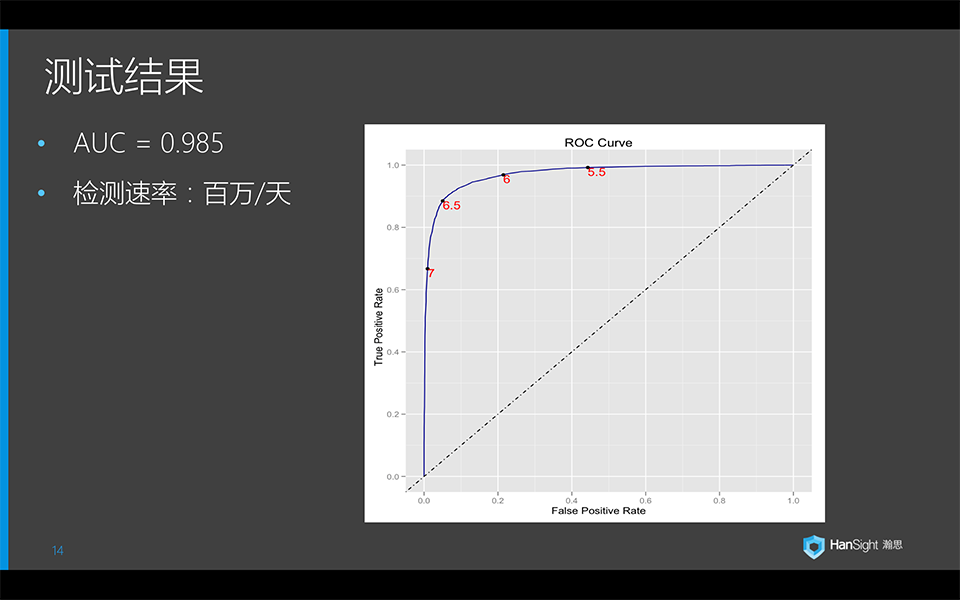
简单说一下测试结果,AUC可以达到0.985,误报率小于1/1000,检测的速度目前可以达到150M/天。

再与各位分享一些经验教训。上面提到检测率和误报率已经同等于沙箱检测的水平。而基于二进制文件的深度学习无需沙箱环境(无需在客户处部署沙箱)。深度学习模型记住的是病毒二进制文件中的有效特征,而不是特征码(特征码由专家选取,对应唯一病毒样本),所以具有更好的通用性。在实际测试中,即使一个月不更新模型,对新衍生的病毒样本也有较高的识别能力。
测试发现,对不同规模的样本进行测试。更大的数据集,有更高的准确度。这个深度学习本身的性质是一致的。再者不能完全把深度学习当成黑箱,而是需要分析其机制,至少要观察哪些样本的哪些特征比重较大。

今年5月爆发的WannaCry席卷了全球90多个国家,造成了很恶劣的影响。上图贴出了Virustotal上各家病毒引擎对早期WannaCry样本的扫描结果。我们可以看到,只有CrowdStrike和Endgame两家使用机器学习为核心的病毒引擎能够将其识别为可疑。这也印证了我们所说的泛化能力强。

另外有一个意外发现是,我们的模型对恶意的HTML检测率也很高。但同时对正常的HTML样本有很高的误报率。定位发现原因是训练集的恶意样本中包含很多HTML内容,被深度学习抽取成了特征。优化方法很简单,只需要在正常样本中加入一定的HTML就可以平衡。
前面提到微软比赛中第一名的方案是有问题的。他的方案是用N-gram产生数万特征,然后用XGboost来做分类。赛后有人发现,微软提供病毒样本时是按病毒分类放在不同路径下,而路径字符是包含在样本中,并被分类器判断成了重要特征。这才使其分类准确度优于其他选手。
上面两个案例都再次提醒我们,不能把机器学习黑箱化。

下一步,我们还会深入到网络中,继续探索具体的检测机制。我们还会测试其他的样本类型,比如文档类型。目前我们的输出只是一个二元判断,那安全人员可能希望可以进一步给出病毒类型,甚至是家族归属。方案层面,除了目前使用的二进制码转低纬度图片+CNN的方法,我们也在测试另一套方案,考察二进制码在长空间跨度下的特征,并应用LSTM。

今天分享先到这,感谢大家!下周还会有我们瀚思高颜值的大数据架构师为大家分享基于Flink的超大规模实时流应用。想加入我们成都或者南京site做大数据/算法开发的,不要犹豫,直接邮件hr@hansight.com。对机器学习和用户行为分析感兴趣的也欢迎直接来勾搭我。

问答环节
Q1: 在文件加壳加密混肴的情况下,系统如何处理? 答:处理加壳样本的方法我在分享中P12已经直接讲到了。
Q2: 现在病毒传播很多靠社会工程学,是用户的正常行为,而且病毒也越来越以获利为目的,不搞破坏,重视隐藏。如果病毒使用gfw对抗方的各种流使量无特征方式,检测系统如何应对呢? 答:现在某些病毒,在行为层面隐藏的比较好,基于行为的检测可能不适用了。那么我也讲到了,基于深度学习的这套检测技术,是基于二进制码的,是直接针对内容的。因为病毒的恶意行为总需要通过某些代码触发,我们即可以通过内容来抽取对应特征并识别。
Q3: 基于深度学习的检测结果的可解释性很低。如果出现了误报,除了whitelist,有没有其他更好的办法? 答:首先我们的误报率是低于千分之一的。另外分享中我提到了,我们可以结合外部信息,比如威胁情报来产生高信息熵的结果。再者因为我们是做2B,对需要二次确认的样本还可以放在我们大数据平台下做前后事件的追溯。
Q4: 可以详细说一下是如何将二进制文件转换为图像的吗?文件大小不一,是如何处理的?还有就是二进制文件有分段处理吗? 答:我们使用改造后的pooling算法,一次性转换,没有分段。
Q5: 对于样本label,除了借助第三方如VT扫描结果,有没有其他更好的方法? 答:我们的样本label包括VT和安全部门自己产生的。
Q6: 您PPT中提到了标准模型和压缩模型,可以详细解释下这两个模型的差异吗 答:简单回答,大的网络参数多,准确度高,但无论是train还是inference的速度都很慢。我们的企业客户很多又没有GPU可以提供。为了提速,我们可以通过剪枝或者选择小网络来训练,只保留几十分之一的参数,缺只损失5%左右的准确度。这也是最近深度学习的一个发展方向。
Q7: PPT中有提到替换最顶和最低几层,这个又是什么意思呢?具体如何替换的呢? 答:输入层的替换主要是对接我们转换后的样本。输出层的替换主要是分类器我们用了lightGBM。
Q8:请问您的方法中是不是只能检测已知的恶意文件,泛化能力这一块大体是个什么水平。 答:如上面介绍的,深度学习模型记住的是病毒二进制文件中的有效特征,而不是特征码,所以具有更好的通用性。即使一个月不更新模型,对新衍生的病毒样本也有较高的识别能力。
Q9:我对这个结果还有点疑惑,理由如下:深度学习本质还是个f(x),效果好的前提是训练和测试的分布有较强一致性,而迁移学习现在进展缓慢。我之前也做过一段时间安全,安全领域现实数据可以说五花八门,一般训练集几乎无法做到跟真实环境分布一致,基于分类的做法我当时感觉更多是学术价值,当然对于dga这种分布明显的是有效的。 答:我们本身就是基于真实环境中的病毒样本来做训练的。安全团队每月都会拿到千万的最新病毒样本,我们也会持续更新模型。这个最终是会应用到客户环境的,并不是一个纯研究性的课题。
Q10:请问一下,训练好的模型,可以在移动终端上运行或自行改良吗?也就是不断应对持续升级的病毒样本。 答:我们还没有测试过在移动端上运行。但是模型是会动态更新的。
comments powered by Disqus