Neo4j简介
Neo4j是一个高性能的图数据库,属于NOSQL数据库中的一类。数据以图的形式存储而不是传统的表结构存储。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性,以及单机存储10亿级数据的能力。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中.
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
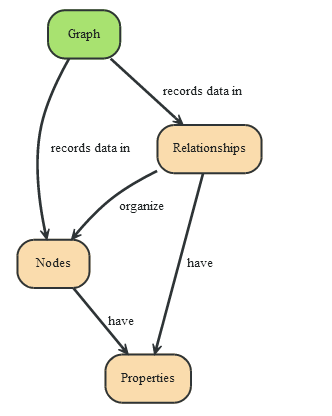
图形数据结构
在一个图中包含两种基本的数据类型:Nodes(节点) 和 Relationships(关系)。Nodes 和 Relationships 包含key/value形式的属性。Nodes通过Relationships所定义的关系相连起来,形成关系型网络结构。
安装
Neo4j可以被安装成一个独立运行的服务端程序,客户端程序通过RESTful API进行访问,也可以通过浏览器Console运行Cypher语句。另外Neo4j支持嵌入式安装,即安装为编程语言的第三方类库,目前只支持java和python语言。同时Neo4j也可以同Gephi结合,成为其插件式数据库源。
因Neo4j是用java语言开发的,所以确保将要安装的机器上已安装了jre或者jdk。
具体教程参见LjHero的这篇博文,本文不再累述。
Cypher简介
Cypher是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询。Cyper通过一系列不同的方法和建立于确定的实践为表达查询而激发的。许多关键字如like和order by是受SQL的启发。模式匹配的表达式来自于SPARQL。正则表达式匹配实现实用Scala。Cypher是一个申明式的语言。对比命令式语言如Java和脚本语言如Gremlin和JRuby,它的焦点在于从图中如何找回(what to retrieve),而不是怎么去做。这使得在不对用户公布的实现细节里关心的是怎么优化查询。
这个查询语言包含以下几个明显的部分:
- MATCH:图形的匹配模式,束缚于开始点。
- WHERE:过滤条件。
- RETURN:返回所需要的。
实战演示
本场实战,我选取了一个邮件头(Email Header)数据集。希望通过构造图数据库,能将邮件的流向关系清晰的展示出来。
数据预处理
原始数据email_headers.csv包含了1170封邮件的数据头部分。数据有四列:From, To, Date, Subject。即发件人,收件人(复数),时间,主题。
经过数据预处理,我将源数据分解为了三个文件:
- addresses.csv: 所有不同的邮件地址,同时加上id。
- emails.csv:所有不同的邮件,以及发送时间和主题。加上id。
- relations.csv:所有的发送,接受邮件关系。包含Email_id,From_id,To_id。
通过预处理,源数据清晰的分解为了图数据的两个组成部分:节点(邮件地址、邮件),关系(发送、接收关系)。
接下来我们启动Neo4j server,打开浏览器Console(默认端口7474),开始使用Cypher加载数据。
清除所有节点和关系
MATCH (n)
OPTIONAL MATCH
(n)-[r]-()
DELETE n,r加载邮件地址,生成Person节点
LOAD CSV是Cypher支持的从CSV文件载入数据的方式。
LOAD CSV WITH HEADERS FROM "file:///home/colin/Downloads/data/addresses.csv" AS csvLine
CREATE (p:Person {id: toInt(csvLine.id), email: csvLine.address })Return 55 nodes.
加载邮件节点。
LOAD CSV WITH HEADERS FROM "file:///home/colin/Downloads/data/emails.csv" AS csvLine
CREATE (e:Email {id: toInt(csvLine.id), time: csvLine.time, content: csvLine.content })Return 1170 nodes.
创建索引
加载关系时需要大量匹配节点。创建节点索引,提升效率。
CREATE INDEX ON:Person(id);
CREATE INDEX ON:Email(id);加载发送、接收关系
-
使用LOAD CSV命令加载大量数据时,可能因为内存限制而失败,产生OutOfMemoryError。这时使用USING PERIODIC COMMIT来分段加载数据。
-
加载关系时,通过MATCH找到对应id的节点,然后创建关系:(节点)-[关系]-(节点)。
-
每封邮件只有一个发件人,用CREATE UNIQUE创建唯一的关系。
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM "file:///home/colin/Downloads/data/relations.csv" AS csvLine
MATCH (p1:Person {id: toInt(csvLine.fromId)}),(e:Email { id: toInt(csvLine.emailId)}),(p2:Person{ id: toInt(csvLine.toId)})
CREATE UNIQUE (p1)-[:FROM]->(e)
CREATE(e)-[:TO]->(p2)Created 10233 relationships, statement executed in 4567 ms.
加载完成,让我们来试验一下查询语句。
查询所有:发件人id=1,收件人id=2的邮件
MATCH (p1:Person)-[r1:FROM]->(e:Email)-[r2:TO]->(p2:Person)
WHERE p1.id = 1 and p2.id=2
RETURN p1,e,p2,r1,r2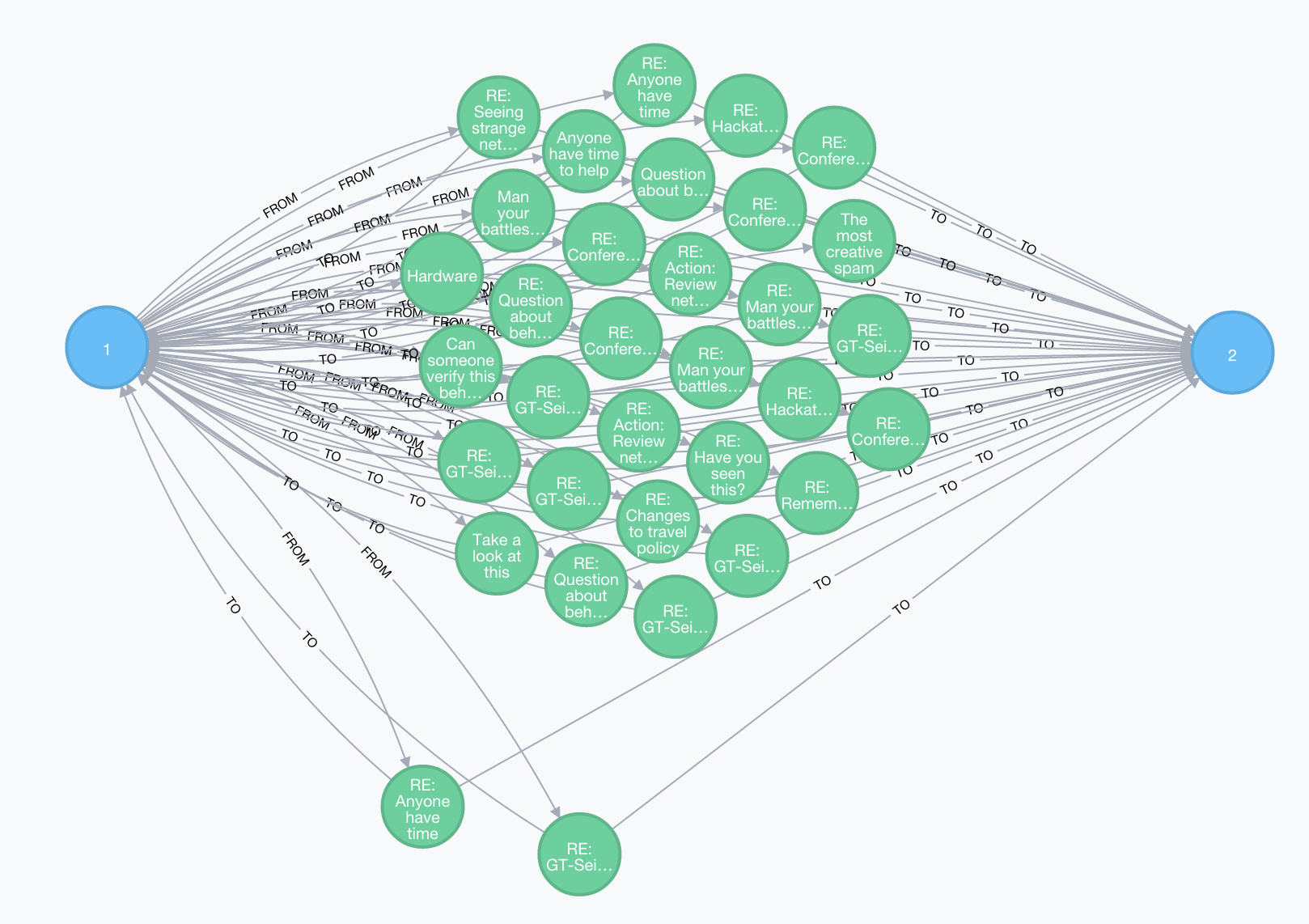
Displaying 35 nodes, 98 relationships.
这里返回了对应节点和关系。我们发现有的邮件收件人也包含了发件人,这个关系并不是很有意义。
查找所有收件人包含发件人的情况,删除这个环形关系。
MATCH (p1:Person)-[r1:FROM]->(e:Email)-[r2:TO]->(p1:Person)
delete r2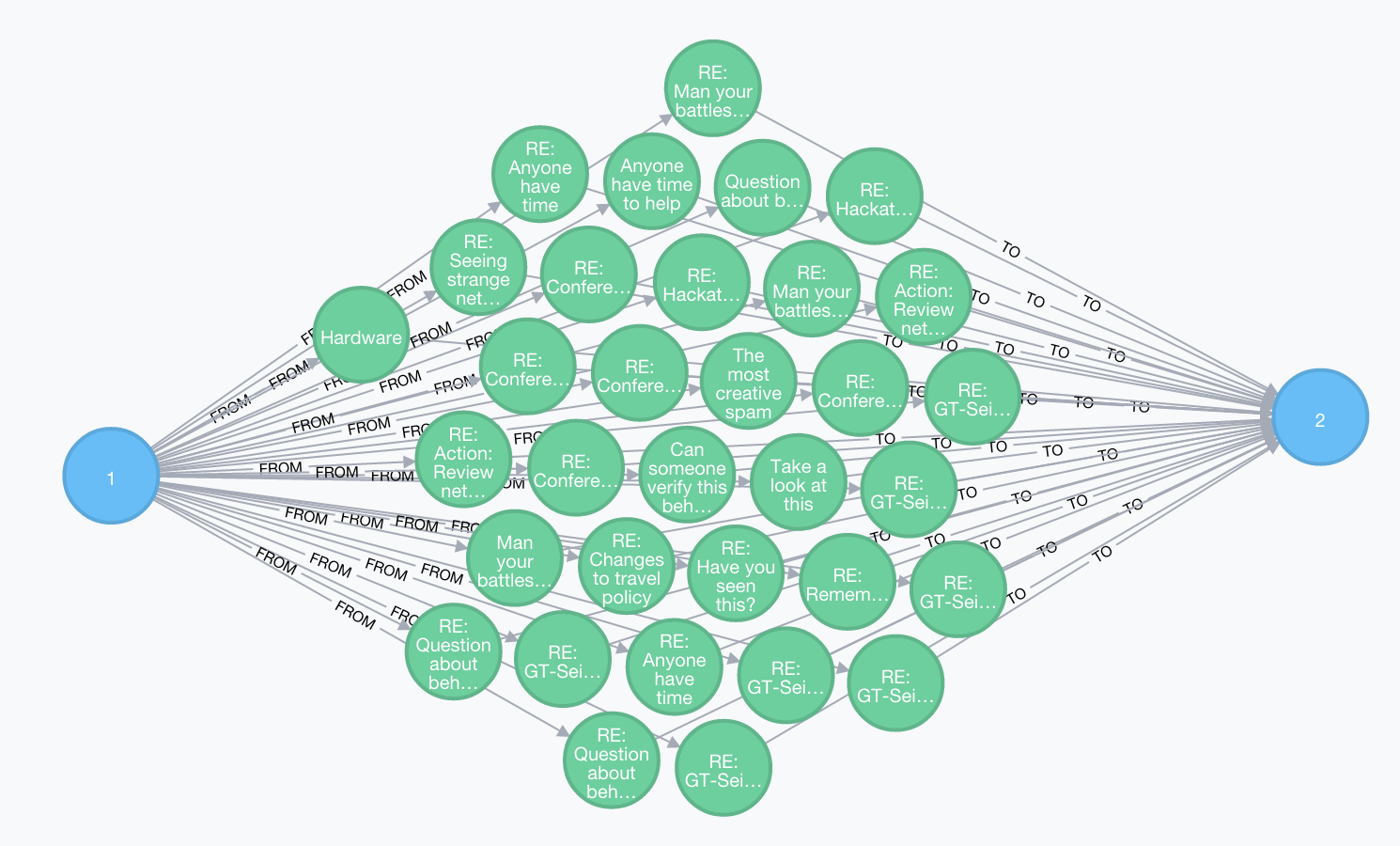
Displaying 35 nodes, 66 relationships.
Cypher也支持对属性进行模糊查询。
通过时间戳来筛选邮件
注意,Neo4j没有内部支持的时间类型,这里我们需要使用正则表达式。
MATCH (p1:Person)-[r1:FROM]->(e:Email)-[r2:TO]->(p2:Person)
WHERE p1.id = 1 and p2.id=2 and e.time=~'^1/16/2014.*'
RETURN p1,e,p2,r1,r2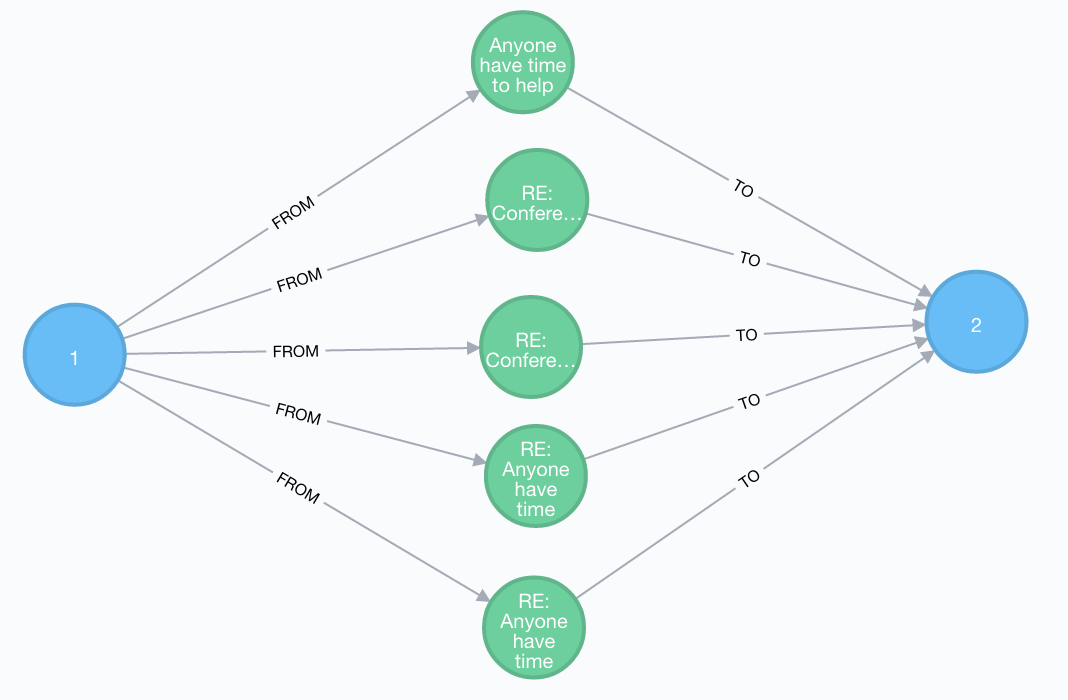
Displaying 7 nodes, 10 relationships.
使用图数据库,我们可以轻易的解决较为复杂的路径问题。
查询所有从A地址到B地址的路径
MATCH p=(:Person {id: 1})-[r:FROM|:TO*1..5]-(:Person {id : 2 })
RETURN p
LIMIT 10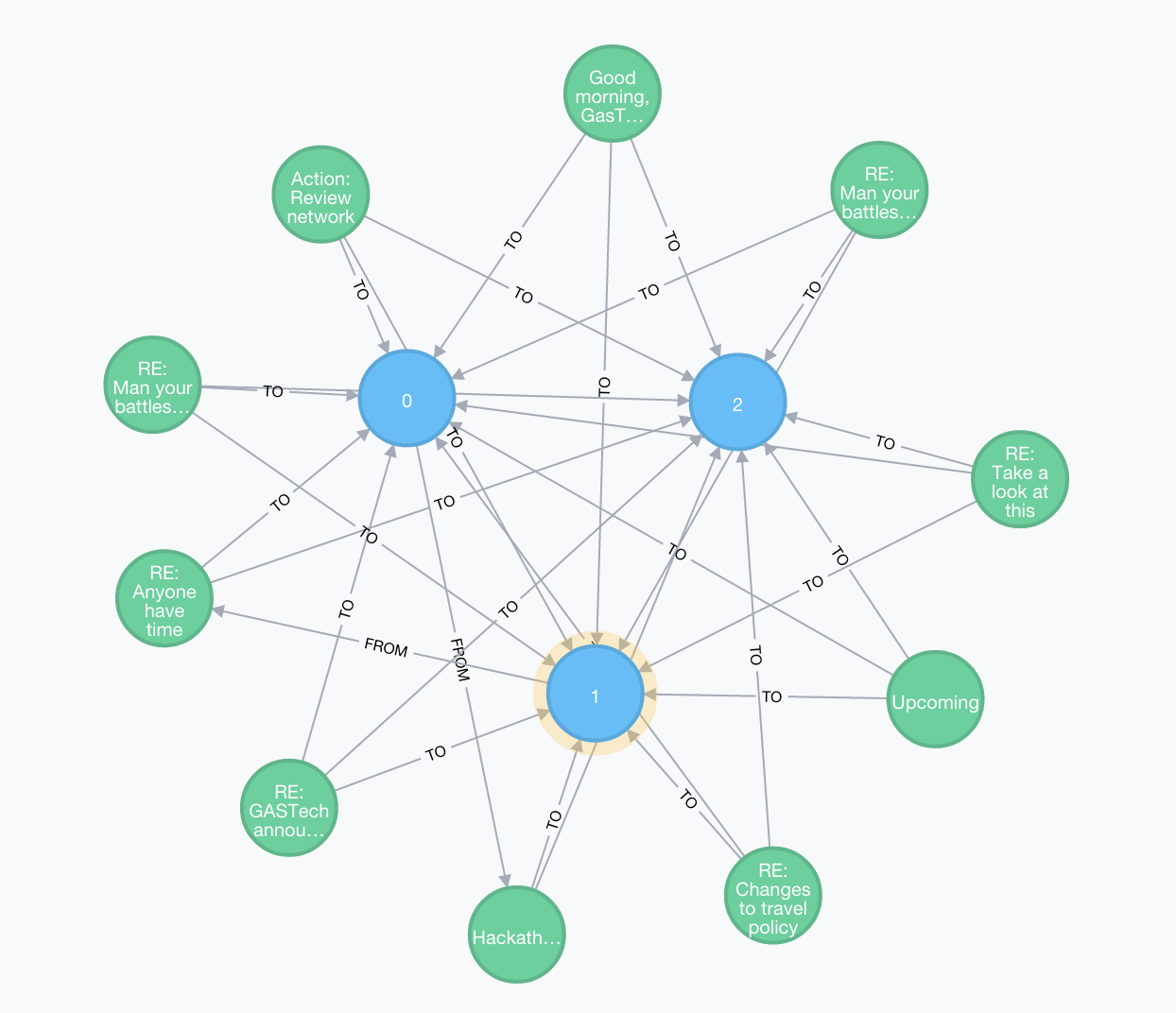
通过COUNT可以做聚合操作。
查询收件人最多的邮件(出度最高)
MATCH (n:Email)-[r:TO]->(x)
RETURN n as Email,
COUNT(r) as ReceiverNumber
ORDER BY COUNT(r) DESC
LIMIT 10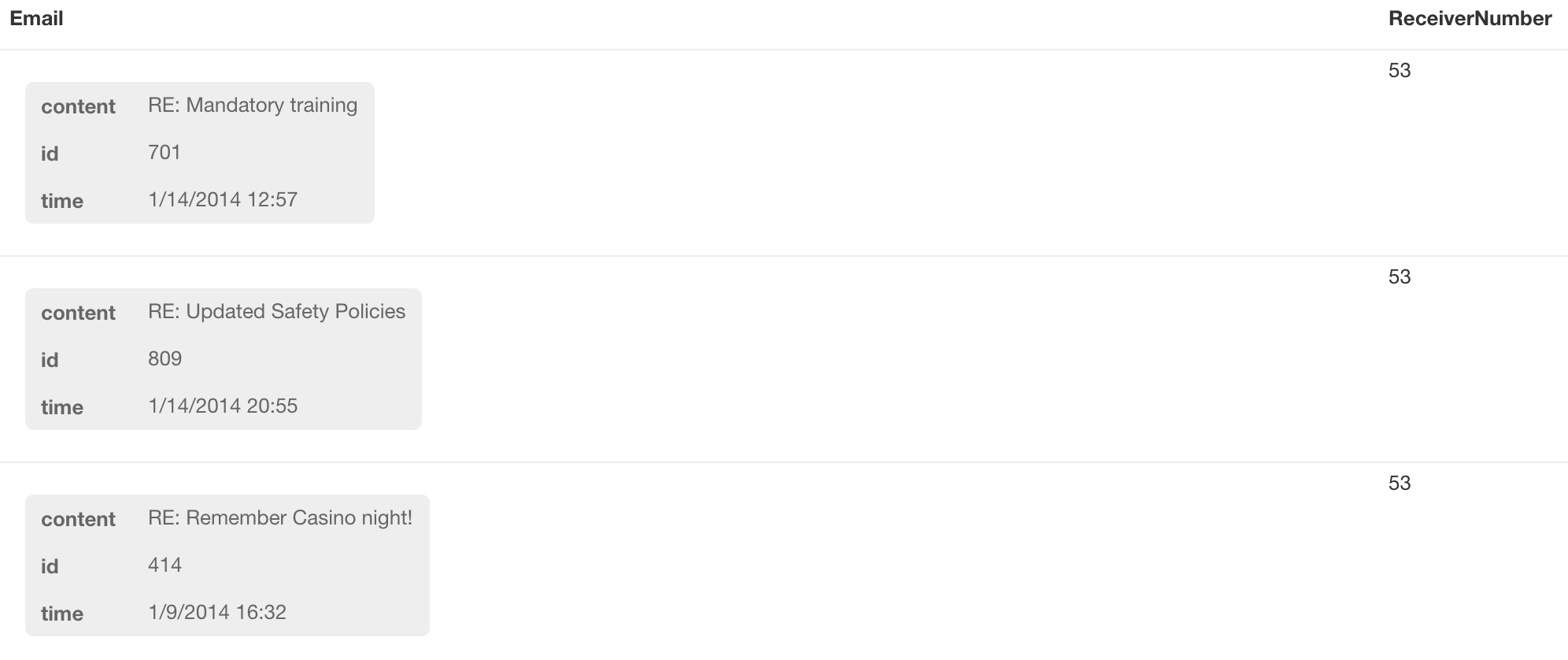
结果显示这些邮件都是发送给所有人的邮件。
小结
通过本次实战,我们实践了:
-
使用LOAD CSV加载CSV格式数据
-
使用USING PERIODIC COMMIT分段加载
-
MATCH来进行匹配查询
-
CREATE来创建节点和关系
-
CREATE INDEX ON来创建索引
-
RETURN返回语句
-
DELETE删除语句
-
使用正则表达式~匹配属性
-
查询路径
-
COUNT聚合操作
通过此文,希望你以及对Neo4j有了一个感性的认识,对Cypher语句有了初步的理解。
comments powered by Disqus