一直没有写过爬虫程序。感觉都不只是遗憾而是一种缺失了。之前在知乎看到类似“能利用爬虫技术做到哪些很酷很有趣很有用的事情?”,又一次激发了我玩一玩爬虫的兴趣。而爬虫的对象就用知乎好了,语言用我最近正在磨砺的Python。
知乎作为知识问答式的网站有很强的社交属性。四月的时候知乎社区酝酿成熟,兴起了一波线下聚会。如何让本来陌生的参与者快速找到共同的痛点,轻松识别大小V?社交网络提供了很好的方法。
先上效果图
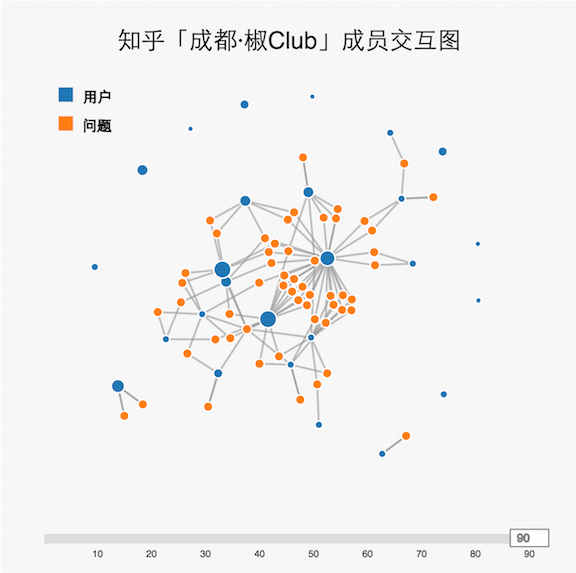
- 用蓝色点表示用户,用橙色点表示问题。点与点的链接表示用户提出或者回答了某个问题。
- 用户的蓝点大小设置是根据关注数取log,既大V大点,小V小点。
- 鼠标在节点停留会显示名称,用户节点还会显示关注数。
其他也有一些可以有的功能,但是为了简化砍掉了。我认为一张图不宜包含过量的信息,而应该让用户保持关注核心信息。新式图表容易包含过量,过杂,或者维度过高的信息。这样看起来炫目,然而并不利于用户使用。
实现细节
Python爬虫现有成熟技术,使用 Beautiful Soup 4 解析 html 文档,使用 requests 处理 http 请求。可以预见已经有前辈做过知乎爬虫。在github搜索以后发现egrcc的zhihu-python fork数高达207。浏览代码以后发现egrcc已经把提取‘问题’,‘用户’,‘回答’等封装的很完美了。
第一步,qq向‘椒Club’组织联络员小麦要到名单,只要id就可以了。
然后遍历id,获得所以Users
users = [User(user_url) for user_url in lines]分别获得每个user的提问和回答
for user in users:
answers = list(user.get_answers())
asks = list(user.get_asks())为了简化图,强化社交熟悉,要求每个问题至少需要和两个以上用户产生链接。
questions = defaultdict(int)
for ask in asks:
questions[ask.get_question().get_title()] += 1
for answer in answers:
questions[answer.get_question().get_title()] += 1
questions = { k:v for (k,v) in questions.iteritems() if v > 1 }最后我们将‘用户节点’,‘问题节点’,‘提问关系’,‘回答关系’一同写入json中,方便后面前段读取。
write_file(usersOut,questionOut,askOut,answerOut)源代码请访问github.com/colin1990324/
前端部分
d3是我前端仅有的经验,这里使用d3.js的force directed graph。
d3提供了d3.layout.force()来处理节点分布。d3.json()直接读取之前生成的图数据。
然后就是添加边和点,这里注意分别设置大小,颜色,文本的提取。
滑动条部分,根据id来显示id<=滑动条的点边,增加一点交互性。这里注意生成图数据的时候,边的Year一定要小于它链接的点的Year,不然就会出现无头边了。
comments powered by Disqus