概述
异常检测,文章中多见为anomaly detection、outlier detection、deviation detection等。在海量的数据中,总有一些不平常的行为潜藏其中,妄图浑水摸鱼,行不轨之事。异常检测算法就像一把精巧的手术刀,准确刻画正常组织的外缘,将各种异常组织依依剔除出来。总诀:归妹趋无妄,无妄趋同人,同人趋大有。
异常检测广泛应用于安全且不限于安全,比如:
- 反欺诈:如电信诈骗,信用卡盗刷,恶意注册、薅羊毛等
- 入侵检测:外部入侵检测
- Insider Threat:内部威胁检测,账户异常、数据泄露等
- 工控、IoT安全:通过各种指标发现工业设施,IoT设备网中的异常
- 生态灾难预警:各种自然灾害,极端天气的预警
- 公共健康:禽流感等传染类疾病的提前发现
- 数据去噪:一些机器学习算法对异常点非常敏感,利用异常检测除去噪声通常是数据预处理中很重要的一步。
大部分的异常检测算法都基于两个基本假设:
- 异常点是稀疏的
- 异常点与正常点特征不一致
基于两点假设,算法通过对主体数据建立正常点的特征基线,从而分离出少量的偏离基线的异常点。
算法分类
一般介绍异常检测的文章会从算法本身的分类出发。我却认为首先要从具体的异常场景出发,用业务的视角带入问题,甚至用不同的视角审视同一个问题。一个异常事件,肯定不会孤立发生,往往能从多个源,多个侧面去发现,相关关联,相互印证,得到完善的全面的场景描述。
异常域
- 数值类异常
- 时间序列异常:应用最多的,无须赘述。
- 周期分解:数据运营用的非常多,减掉周期后可检测异常点。
- 历史基线:同一主体,以历史数据建立基线。
- 群体基线:以主体所在的群体数据建立基线,检测离群主体。
- 统计模型:基于数值分布的异常检测,需要先假设数据符合某一种分布模型。
- 游离点检测:在高维特征下,检测游离点。
- 关联关系类异常
- 新的关联关系:分析主体关联到新的实体,如登录新的设备。
- 短时多个关联关系:分析主体在短时间内关联多个实体,如10分钟内登录10台设备。
- 非法的关联关系:分析主体与实体的关联是非法的或者违反逻辑的,如手淘登录来源IP来自数据中心。
- 行为序列类异常
- 按发生时间构建一个主体的行为序列,建立历史基线。小概率序列认为是异常。
- 文本类异常
- 凡涉及到文本或字符串的异常,如垃圾邮件检测、webshell检测、xss检测、钓鱼邮件检测。
- 图像类异常
- 图像中的异常检测。
- 网络中的异常
- 将网络流量,行为构建为网络后,可以做基于网络的异常检测。常应用在反洗钱、反欺诈、网络安全中。
- 地理位置类异常
- 移动速度异常:时间临近行为发生的地理位置偏差过大,国外称为land speed violation。
- 地理位置基线:对日常活动范围建立基线。
以上异常域每一个都从不同的视角切入。一个异常行为发生以后,让我们有多种不同的方式,不同的能力去检测发现,同时互为印证。无监督学习的业务刻画能力是有限的,基于多视角的检测能够很好的补偿算法本身的局限。
算法域
最全无监督异常检测算法分类在此:
- 基于密度的
- KNN、DBScan、KMeans:常见的密度聚类算法,小簇或者游离点为异常。如下图

- LOF:根据数据点周围数据的密度来判断此数据是否为异常,所以是基于neighbor density的。
- KNN、DBScan、KMeans:常见的密度聚类算法,小簇或者游离点为异常。如下图
- 基于矩阵分解的
- Robust PCA:将输入矩阵M分解为了低秩矩阵L+稀疏矩阵S+噪声N。如下图中输入图像被分解为背景和稀疏的动态人物。RPCA可以广泛应用在时间序列异常、基于基线的异常和基于特征的异常检测中。

- Robust PCA:将输入矩阵M分解为了低秩矩阵L+稀疏矩阵S+噪声N。如下图中输入图像被分解为背景和稀疏的动态人物。RPCA可以广泛应用在时间序列异常、基于基线的异常和基于特征的异常检测中。
- 基于神经网络的
- Replicator NN:也就是AutoEncoder,自还原网络。数据特征被压缩在网络参数中,正常数据通过网络可以完美还原,但是异常数据通过网络后不能被还原。
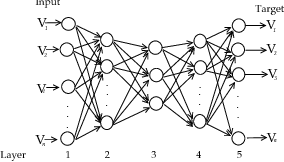
- GAN:对抗网络在最近也被应用在视频异常检测中。在没有标记数据的情况下,加入时间维度,通过对抗网络识别出视频中的异常动态。
- Replicator NN:也就是AutoEncoder,自还原网络。数据特征被压缩在网络参数中,正常数据通过网络可以完美还原,但是异常数据通过网络后不能被还原。
- 基于分布的
- 高斯分布:训练得到期望μ和方差σ^2,再确定阈值ε。
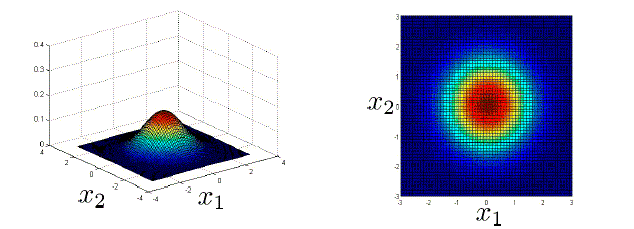
- 混合模型分布:两个以上混合概率分布。
- HBOS: Histogram-based Outlier Score,一定程度上依赖空间划分。
- 高斯分布:训练得到期望μ和方差σ^2,再确定阈值ε。
- 基于序列的
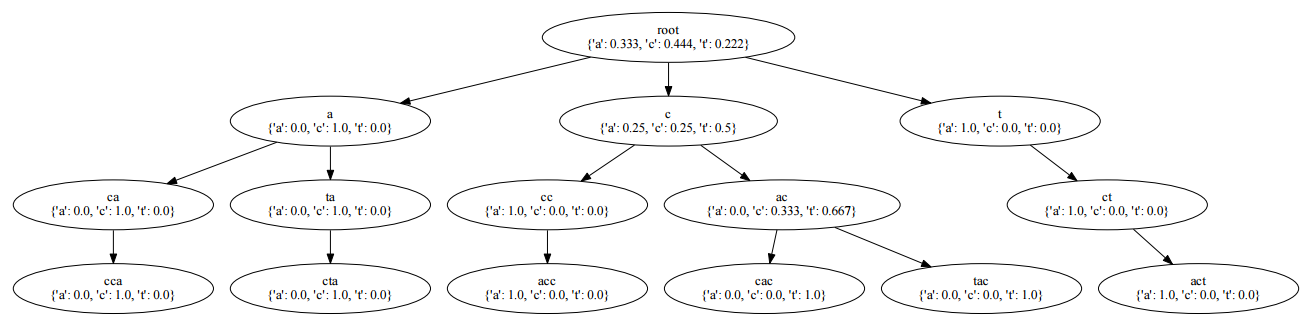
- HMM:隐马尔科夫模型,训练得到状态转移矩阵,进而计算序列发生的概率。
- PST:概率后缀树,将行为构建为字符串,进而通过概率后缀树学习子串的发生概率。
- 基于树的
- Iforest:其实是基于森林的mass ensemble方法。在异常检测领域独树一帜,随机采样下健壮性也很强,适合高纬度的数据。周老师抓住了一个ground truth,即通过随机的属性和划分点,一些样本很快就到达了叶子节点(即叶子到根的距离d很短),那么它们很有可能是异常点。因为那些路径d比较短的样本,都是距离主要的样本点分布中心比较远的。
- 基于图的
- 传统子图特征:基于图的点、边数量、出入度信息、n度关联等信息构建特征集,进而检测异常点。
- Egonet:唯一中心节点(ego),以及这个节点的邻居(alters)组成的子图。特征如上。
- network2vector:常见的算法如random walk,通过随机游走构建图的vector embedding。
- 基于分类的
- one-class SVM:虽然是分类,但其实是正常点在一边,异常点在另一边。好处是可以用SVM的各种kernel。
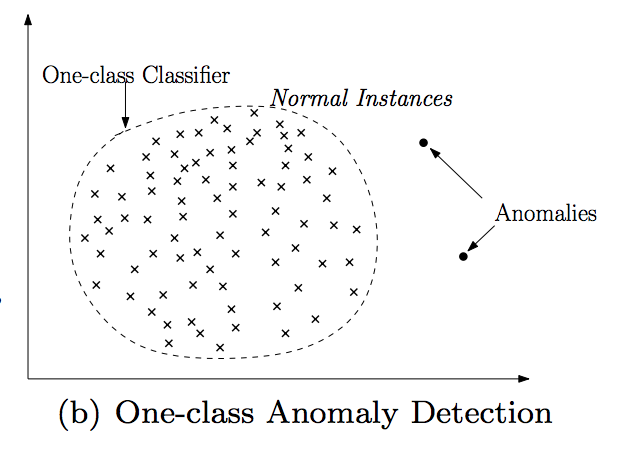
- one-class SVM:虽然是分类,但其实是正常点在一边,异常点在另一边。好处是可以用SVM的各种kernel。
- 基于时序的
- 平滑模型:Moving Average Model、Olympic Model
- 回归模型:Regression Models
- 周期分解:seasonal decomposition
具体的算法细节不再累述,大家能google到许多文章。
应用举例
那上文中的两种视角如何结合使用呢?举一个异常登录的场景,黑客H尝试使用社工库破解账户A的密码。

结合异常域,我们知道可以从以下方向入手:
- 数值类:登录的时间是否符合周期、登录的次数、登录失败的次数等是否符合个群基线
- 关联关系:登录的设备对A是否是新设备、登录的设备是否登录了很多不同账户、登录的IP对A是否是新IP、IP是否是黑名单IP
- 行为序列:是否符合登录->浏览->下单->付款等大概率序列。结合人机识别数据,键盘、鼠标操作轨迹是否符合人的行为模型。
- 网络图:将账户A、IP、浏览器特征、设备特征、访问的url、服务等实体构件为图。与所有登录行为一同计算异常。
- 地理位置:登录的位置是否在日常正常范围内(省市区、经纬度距离),与上次记录到的行为做比对,是否符合正常的移动速度。
然后针对每个可能的异常角度,我们再在算法域中寻找对应能够应用的算法,对应具体业务设置参数和阈值。从而完整的检测登录异常这个场景。
如何评价无监督算法
如何给算法输出的异常打分其实是一个非常头疼的问题,但针对不同模型我们也不失一些标准方法。
拉依达准则
如果整体数据服从一元正态分布,则P(|x-μ |>3σ )<0.003,因此当数据对象值偏离均值3倍方差的时候,就认为该数据对象为异常点。
Mahalanobis距离
 其中S为二元高斯分布的协方差矩阵,x上横为所有数据对象的均值。Mahalanobis距离越大,数据对象偏离均值越大,也就越异常。
其中S为二元高斯分布的协方差矩阵,x上横为所有数据对象的均值。Mahalanobis距离越大,数据对象偏离均值越大,也就越异常。
聚类评价
在没有标签的情况下,根据聚类本身的特点,每个簇可以计算两个指标。一个是类内点间的平均距离I,一个是与类外点的平均距离O。那么I除以O就可以用于描述聚类结果的内聚度,俗称类内聚合度、类间低耦合。
Reconstruction Error
重构偏差也可以直接用作异常分。比如RPCA中的sparse矩阵,Replicator NN中还原向量与原始向量的差值。当然分母还要好好设计一下。
小结
异常检测有非常广的应用领域,从网络安全到人体健康到自然灾害预测。甚至我们的大脑也运行着异常检测的程序。周一看到某个男同事剃了头,和大脑中飘逸发型的基线不匹配了。技术团队outing了发照片,一眼找出其中唯一的程序媛。
在不同业务场景中可能出现不同的异常域,相应的要用不同特性的算法去检测。最好是利用多种算法的不同视角去共同刻画,得到更准确更全面的结果!
comments powered by Disqus